🎉 Exciting news! SEACrowd’s very first publication has been accepted at EMNLP 2024! 🚀
“SEACrowd: A Multilingual Multimodal Data Hub and Benchmark Suite for Southeast Asian Languages”
This milestone is a massive leap for AI research in Southeast Asia, and we owe it all to our dedicated 100+ contributors. Your commitment and hard work were pivotal in bringing us to this point. 💪 Also special thanks to AI Singapore who has been very supportive and encouraging for our journey. ❤️
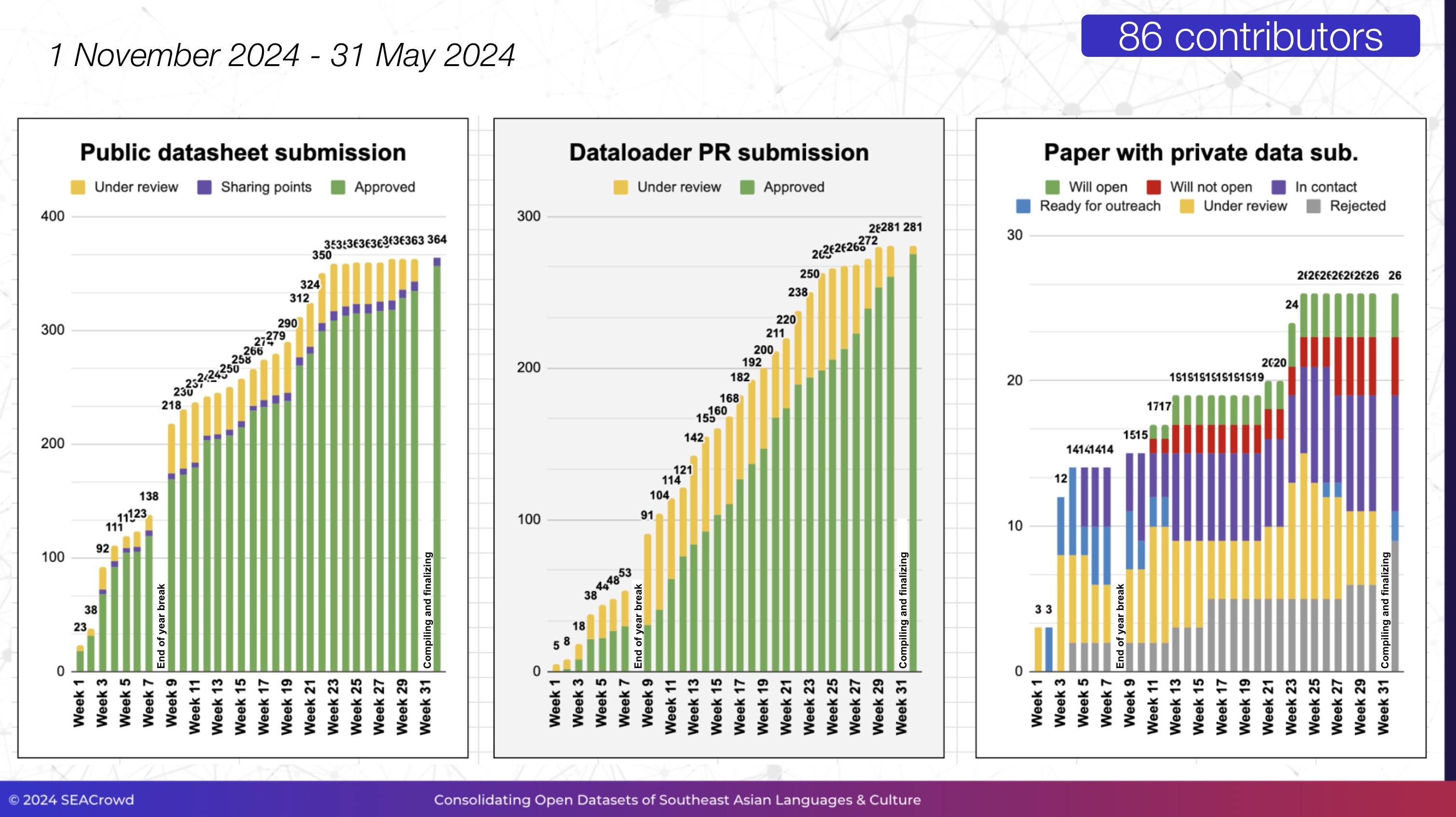
Our first collaboration spanned from 1 Nov 2023 to 15 Jun 2024, with an incredible team of 86 co-authors and 23 contributors. Together, we consolidated 498 datasheets into the SEACrowd Catalogue (web/csv) and standardized 399 dataloaders within the SEACrowd Data Hub, covering 980 out of 1,300+ Southeast Asian languages.
Through our SEACrowd Benchmarks, we evaluated AI models across 36 indigenous languages on 13 tasks, offering deep insights into the current AI landscape in Southeast Asia 🌏. Our work also proposes strategies to drive future AI advancements across the region.
Looking ahead, the SEACrowd community is gearing up for even more exciting initiatives! From another crowdsourcing project launching in November 2024 (stay tuned! 😉), to SEA engagement events like Birds-of-a-Feather at EMNLP 2024, and the on-going pilot SEACrowd Apprentice program designed to help aspiring researchers kickstart their journey in AI.
The future of AI in Southeast Asia is brighter with all of us working together! 🌟
Keep updated for the next projects!
Other important URLs:
Other Details
Timeline

How did they become contributors?
Generally, anyone could contribute as much as they wanted and as little as they wanted! However, in order to reward contributors fairly, we came up with a contribution point system.
Contribution Point
Each confirmed contribution was rewarded with points. The details of the contribution point system were provided in SEACrowd Data Hub. A general rule of thumb is that the more complex the task was, the higher the number of points it would earn you.
For example, since our goal was to open access to as many NLP datasets as possible, releasing their own private data should earn them a substantial number of points, especially if the languages were rare and the data quality was superb.
Once their points reached 20, they would be rewarded with merchandise and co-authorship. For co-authorship, the number of their contribution points would determine their position in the authorship list in our publication.
The contribution point tracking for this past project is available at this sheet!